主页 > 经验 >
如何提取pdf中的文字内容 如何从pdf中提取文字的方法
如何提取pdf中的文字内容 如何从pdf中提取文字的方法。我们都知道电脑中有一种PDF的格式文件,这是我们经常需要遇到的电脑格式文件。那么当我们想要提取PDF格式文件中的文字内容,应该具体怎么去操作呢?一起来看看吧。
首先运行Adobe Acrobat X Pro软件,打开你要提取文字的pdf文档,如下图所示:

定位到你想要提取文字的页面,选中,点击右键可以看到,当前页面是一张图片,如下图所示:
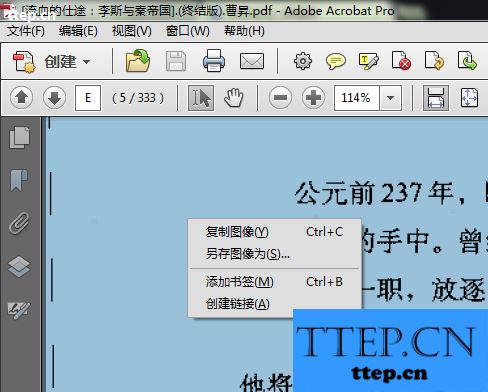
在Adobe Acrobat X Pro软件工具栏右侧,依次找到工具――识别文本,如下图所示:
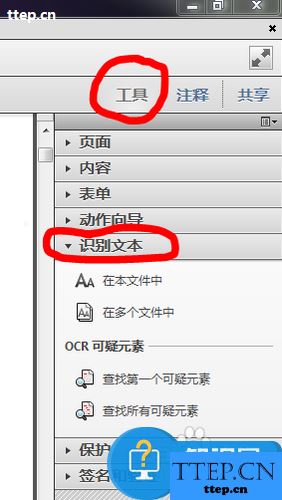
点击“在本文件中”,弹出识别文本的窗口,为了方便,我选择了当前页面,设置中内容一般不用设置,如有需要可以点击编辑,更改设置项目,如下图所示:

点击“确定”后,软件会自动分析当前页面,然后自动识别其中的文本,如下图所示:

识别完成后,仍然停留在当前页面,不同的是,当再次选择其中的文本点击右键后,就能看到熟悉的复制,也可以选择“将选定项目导出为…”,如下图所示:

复制完成后,将其粘贴到文本文档中或者你需要的地方就可以了,如下图所示,pdf中的文字就这样提取出来了。
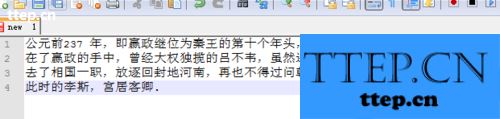
对于我们遇到了这样的需要操作的问题的时候,就可以按照上面给你们介绍的详细解决方法,希望能够对你们有所帮助。
首先运行Adobe Acrobat X Pro软件,打开你要提取文字的pdf文档,如下图所示:

定位到你想要提取文字的页面,选中,点击右键可以看到,当前页面是一张图片,如下图所示:

在Adobe Acrobat X Pro软件工具栏右侧,依次找到工具――识别文本,如下图所示:

点击“在本文件中”,弹出识别文本的窗口,为了方便,我选择了当前页面,设置中内容一般不用设置,如有需要可以点击编辑,更改设置项目,如下图所示:

点击“确定”后,软件会自动分析当前页面,然后自动识别其中的文本,如下图所示:

识别完成后,仍然停留在当前页面,不同的是,当再次选择其中的文本点击右键后,就能看到熟悉的复制,也可以选择“将选定项目导出为…”,如下图所示:

复制完成后,将其粘贴到文本文档中或者你需要的地方就可以了,如下图所示,pdf中的文字就这样提取出来了。

对于我们遇到了这样的需要操作的问题的时候,就可以按照上面给你们介绍的详细解决方法,希望能够对你们有所帮助。
- 最近发表
- 赞助商链接